Классификация объектов
Метод kNN - k ближайших соседей
Метод k-ближайших соседей не нуждается в предварительной фазе обучения и начинает классифицировать точки данных на основе большинства голосов их соседей.
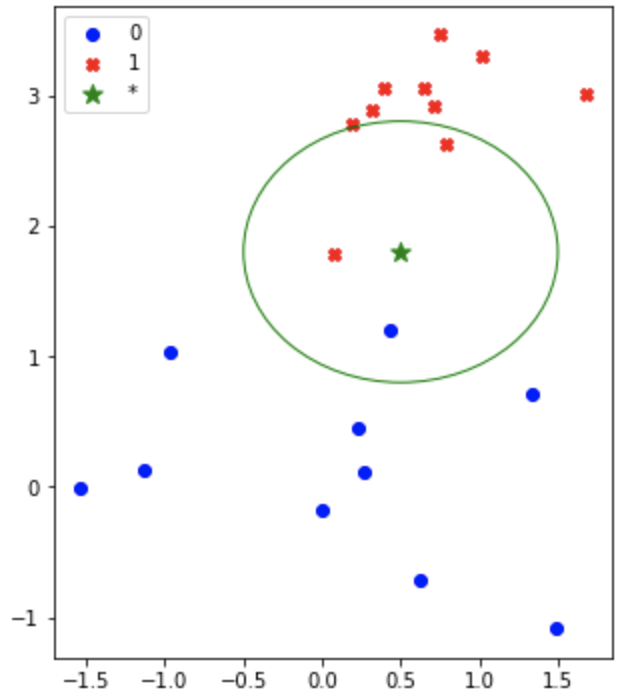
Применение метода kNN с использованием sklearn
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
class KNeighborsClassificator:
def __init__(self, random_state=42):
self.model = None
def fit(self, X_train, y_train):
self.model = KNeighborsClassifier(n_neighbors=30)
self.model.fit(X_train, y_train)
def predict(self, X_test):
y_test = self.model.predict(X_test)
return y_test
file_name = "file.csv"
csv_file_path = dir_path + file_name
data = pd.read_csv(csv_file_path, sep=';')
XY = data.values
Xm = XY[:,:-1]
Y = XY[:,-1]
# Разделим выборку на тестовую и тренировочную
x_train, x_test, y_train, y_test = train_test_split(Xm, Y, train_size=0.7, random_state=42)
knn = KNeighborsClassificator()
knn.fit(x_train, y_train)
y_predicted = knn.predict(x_test)
print(f'Точность на обучающей выборке= {metrics.accuracy_score(y_train, knn.predict(x_train))}')
print(f'Точность на тестовой выборке= {metrics.accuracy_score(y_test, y_predicted)}')
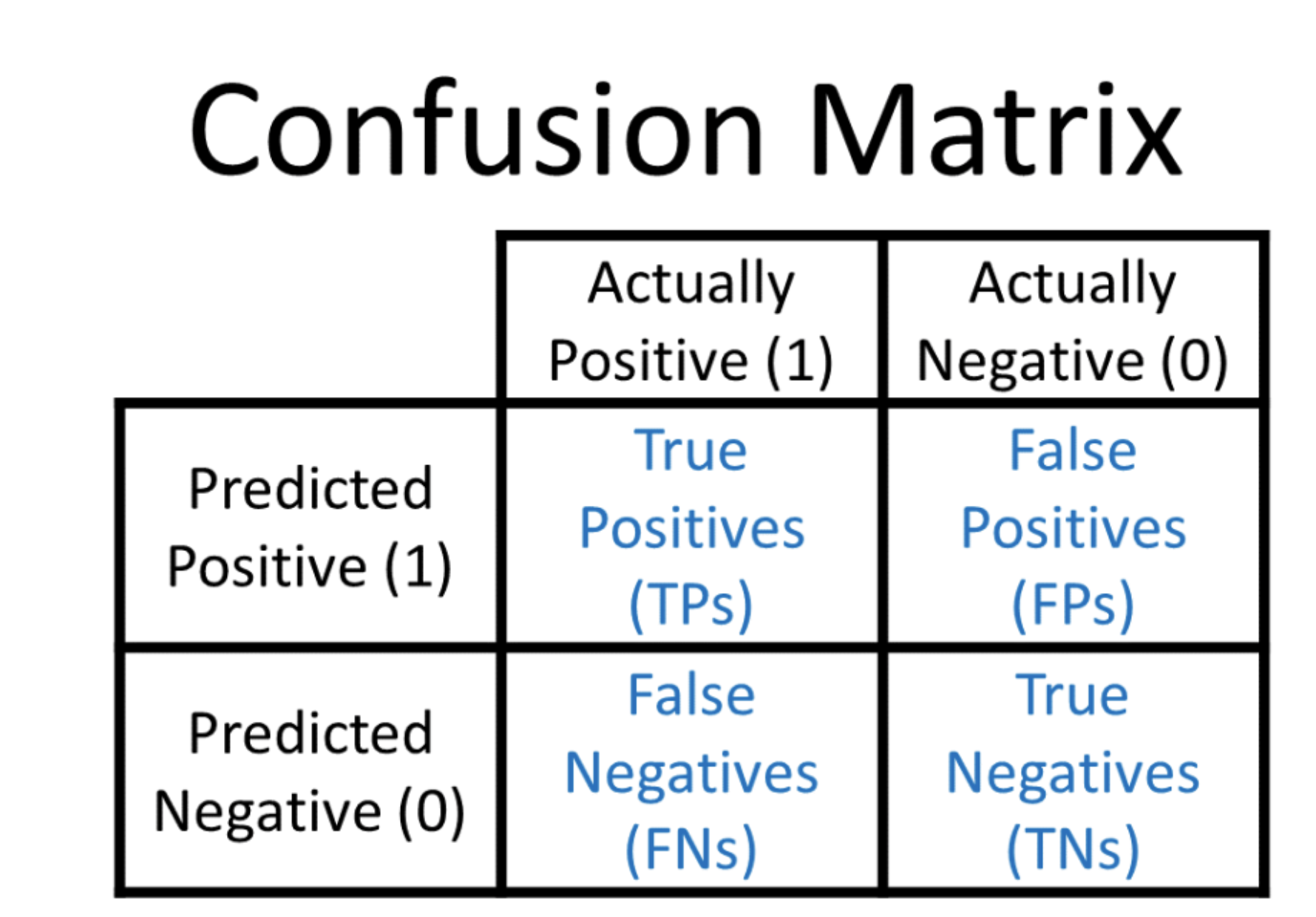
print(f'Матрица соответсвия: \n {metrics.confusion_matrix(y_test, y_predicted)}')
# Точность на обучающей выборке= 0.6767515923566879
# Точность на тестовой выборке= 0.6888888888888889
# Матрица соответсвия:
# [[148 37]
# [ 47 38]]
Классификация при помощи логистической регрессии
Также добавим предикторы и шкалирование
from sklearn.linear_model import LogisticRegression
class LogregClassificator:
def __init__(self, C=1.0, random_state=42):
self.log_reg = LogisticRegression(C=C, random_state=random_state)
self._model = None
self._scaler = MinMaxScaler()
def get_model(self):
return self._model
def __extend_data__(self, X):
"""
Добавление предикторов
"""
nn = X.shape[1]
Xnew = X.copy()
for i in range(nn-1):
for j in range(i, nn):
Xnew = np.hstack([Xnew, (X[:,i]*X[:,j]).reshape((len(X),1)) ])
Xnew = np.hstack([Xnew, (X[:,nn-1]*X[:,nn-1]).reshape((len(X),1)) ])
return Xnew
def fit(self, X_train, y_train):
Xnew_train = self.__extend_data__(X_train)
self._scaler.fit(Xnew_train)
Xnew_train = self._scaler.transform(Xnew_train)
self._model = self.log_reg.fit(Xnew_train, y_train)
def predict(self, X_test):
Xnew_test = self.__extend_data__(X_test)
Xnew_test = self._scaler.transform(Xnew_test)
y_test = self._model.predict(Xnew_test)
return y_test
log_reg = LogregClassificator(C=0.1)
log_reg.fit(x_train, y_train)
model = log_reg.get_model()
print('a0=', model.intercept_)
# a0= [-3.34]
print(model.coef_)
# [[0.26 0.29 0.49 0.39 0.15 0.16 0.33 0.2 0.13 0.29 0.17 0.4 0.26 0.32]]
y_predicted = log_reg.predict(x_test)
print(f'Точность на обучающей выборке= {metrics.accuracy_score(y_train, log_reg.predict(x_train))}')
print(f'Точность на обучающей выборке= {metrics.accuracy_score(y_test, y_predicted)}')
# Точность на обучающей выборке= 0.678343949044586
# Точность на обучающей выборке= 0.6925925925925925
print(f'Матрица соответсвия: \n {metrics.confusion_matrix(y_test, y_predicted)}')
# Матрица соответсвия:
# [[148 37]
# [ 46 39]]